Lecture summary: Programming Techniques for Scientific Simulations
During the autumn semester of 2017 I took the course “Programming Techniques for Scientific Simulations” as part of my BSc course in Computational Science and engineering at ETH Zürich.
This is a summary of the course’s contents I wrote and used during the actual exam. Some things are missing, as it was an open-book exam and I also used other resources, for instance the lecture slides. In particular, I didn’t include much Python and C++ meta-programming (expression templates).
The course primarily focuses on C++ and its uses for scientific computing, but also covers other frequent tools like git, make, cmake and Python. It is not a basic C++ tutorial, rather it assumes prior experience with this programming language and covers some more advanced techniques for professional and scientific computing.
Here are some more in-depth articles about content covered in the lecture I wrote in the course of the semester:
- Setting up git for the first time
- Git cheat sheet
- Automating builds with make
- Making C++ libraries
- CMake basics
- Introduction to plotting with Python and Matplotlib
C++ linking
main.cpp ---preprocessor--- > main.ii ---compiler--- > main.s ---assembler--- > main.o
|
libsomething.a somefile.o someguy.o |
| | | |
--------------------------------------------------------------linker
|
v
main.exe
Manually linking files
File layout:
/
main.cpp
include/
square1.h
square2.h
square1.cpp
square2.cpp
lib/
libsquare.a
bin/
square1.o
square2.o
main.o
main.exe
Suppose main.cpp requires square1.cpp and square2.cpp:
$ cat main.cpp
#include "square1.h"
#include "square2.h"
int main () {
...
}
Now to compile this project we need to compile square1 and square2 separately, then link main.cpp against them:
g++ -c square1.cpp
g++ -c square2.cpp
g++ -c main.cpp
g++ main.o square1.o square2.o -o main.exe
Making static libs
g++ -c square1.cpp # Compile files for lib
g++ -c square2.cpp
ar ruc libsquare.a square1.o square2.o # Create archive
ranlib libsquare.a # Add table of contents
g++ main.cpp -Iinclude -Llib -lsquare # Compile linking against static lib
-I: location of header files-L: location of binaries-l: libraries to look for (squareindicates filelibsquare.a)
As a Makefile
$ cat Makefile
FLAGS = -Wall -Wpedantic -Wextra
B = bin
.PHONY: all
all: bin/main.exe
bin/main.exe: main.cpp lib/libsquare.a
$(CXX) ${FLAGS} $< -Iinclude -Llib -lsquare -o $@
lib/libsquare.a: $B/square1.o $B/square2.o
ar ruc $@ $^ # Create archive
ranlib $@ # Add table of contents
$B/square%.o: include/square%.cpp # A target for each of square1.o and square2.o
g++ -c $< -o $@
.PHONY: clean
clean:
rm -f $B/*
rm -f lib/*.a
$^: all dependencies of this target.$<: the first dependency of this target$@: this target$?: all out-of-date dependencies$(CXX): the default C++ compiler${FLAGS}: call custom variable. Note that if the variable name is only one character, e.g.B, the braces can be omitted:$B.
Using CMake
Create a file called CMakeLists.txt in the include/ directory:
~/squaretest/include$ cat CMakeLists.txt
# Minimum required version of CMake
cmake_minimum_required(VERSION 2.8)
# Project name
project(Square_lib)
# Create the square library
add_library(square square1.cpp square2.cpp)
# Allow files linking against this library to find the header files for this lib
target_include_directories(square PUBLIC ${CMAKE_CURRENT_SOURCE_DIR})
Then create one in the root of the project:
/squaretest/$ cat CMakeLists.txt
# Minimum required version of CMake
cmake_minimum_required(VERSION 2.8)
# Project name
project(demo)
# Required C++ standard
set(CMAKE_CXX_STANDARD 11)
# Flags for our compiler. Extend the existing flags
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Wall -Wextra -Wpedantic")
# Tell CMake
add_executable(main.exe main.cpp)
# Recurse into subdirectories, executing the CMakeLists.txt in there
add_subdirectory(include/)
# Link our executable to the square library
target_link_libraries(main.exe square)
Now we can navigate to a build directory and execute CMake. This will create a Makefile which we can use to build the project!
~/squaretest/$ mkdir build
~/squaretest/$ cd build
~/squaretest/build$ cmake ..
-- The C compiler identification is GNU 5.4.0
-- The CXX compiler identification is GNU 5.4.0
-- Check for working C compiler: /usr/bin/cc
-- Check for working C compiler: /usr/bin/cc -- works
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Detecting C compile features
-- Detecting C compile features - done
-- Check for working CXX compiler: /usr/bin/c++
-- Check for working CXX compiler: /usr/bin/c++ -- works
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Configuring done
-- Generating done
-- Build files have been written to: ~/squaretest/build
~/squaretest/build$ make
Scanning dependencies of target square
[ 20%] Building CXX object include/CMakeFiles/square.dir/square1.cpp.o
[ 40%] Building CXX object include/CMakeFiles/square.dir/square2.cpp.o
[ 60%] Linking CXX static library libsquare.a
[ 60%] Built target square
Scanning dependencies of target main.exe
[ 80%] Building CXX object CMakeFiles/main.exe.dir/main.cpp.o
[100%] Linking CXX executable main.exe
[100%] Built target main.exe
Installing with CMake
Add the following line to the file project/CMakeLists.txt from before:
install(TARGETS main.exe DESTINATION bin)
And then these to the file project/include/CMakeLists.txt:
install(TARGETS square
ARCHIVE DESTINATION lib
LIBRARY DESTINATION lib
)
install(FILES square1.h square2.h DESTINATION include)
Now we can run cmake again in the build/ directory, but this time specifying a prefix for the install location (or leave it at the default):
~/squaretest/$ cd build
~/squaretest/build/$ cmake -DCMAKE_INSTALL_PREFIX=~/square_install ..
-- The C compiler identification is GNU 5.4.0
-- The CXX compiler identification is GNU 5.4.0
-- Check for working C compiler: /usr/bin/cc
-- Check for working C compiler: /usr/bin/cc -- works
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Detecting C compile features
-- Detecting C compile features - done
-- Check for working CXX compiler: /usr/bin/c++
-- Check for working CXX compiler: /usr/bin/c++ -- works
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Configuring done
-- Generating done
-- Build files have been written to: ~/squaretest/build
~/squaretest/build$ make install
Scanning dependencies of target square
[ 20%] Building CXX object include/CMakeFiles/square.dir/square1.cpp.o
[ 40%] Building CXX object include/CMakeFiles/square.dir/square2.cpp.o
[ 60%] Linking CXX static library libsquare.a
[ 60%] Built target square
Scanning dependencies of target main.exe
[ 80%] Building CXX object CMakeFiles/main.exe.dir/main.cpp.o
[100%] Linking CXX executable main.exe
[100%] Built target main.exe
Install the project...
-- Install configuration: ""
-- Installing: ~/square_install/bin/main.exe
-- Installing: ~/square_install/lib/libsquare.a
-- Installing: ~/square_install/include/square1.h
-- Installing: ~/square_install/include/square2.h
~/squaretest/build/$ cd ~/square_install/bin/
~/square_install/bin/$ ./main.exe
Generic Programming
- Identify useful and efficient algorithms
- Find their generic representation
- Categorize functionality of some of these algorithms
- What do they need to have in order to work in priciple?
- Derive a set of (minimal) requirements that allows these algorithms to run efficiently
- Categorize these algorithms and their requirements
- Are there overlaps, similarities?
- Construct a framework based on classifications and requirements
- Now realize this as a software library
Example: minimum function
template <typename T>
T min(T const& x, T const& y) {
return (x < y) ? x : y;
}
Requirements on T:
– operator< returning a result convertible to bool
– Copy-constructible (for return value!)
template <typename T>
T const& min(T const& x, T const& y) {
return (x < y) ? x : y;
}
Now we removed copy-constructability constraint!
Typedef and using
Allow for more code readability, maintainability, and portability.
typedef unsigned short int age_t;
# Same as
using age_t = unsigned short int;
Classes
mutablemembers can be modified even in aconstinstance of the class, or inside aconstmethod.friends are functions/classes that get access to the private members of this class.thisis defined within each members function and is a pointer to the current instance.staticmembers are shared across all instances of the class. Static properties must be declared and defined in the source for it to link. Static methods may only access static properties of the class!
class X {
mutable int i;
public:
void f(const int * const a);
void g(const int & a) const;
friend void h(...);
friend class Y;
};
X x1;
const X x2;
Class templates
Class templates can take either types or objects as parameters:
template <double B = 0, typename T> // Template argument, template type
class X {
T elem;
double l;
public:
void f() { l += B; }
};
X<3.14, bool> x;
Class templates can have specializations:
template <typename T>
class X {
public:
void f () { std::cout << "Generic template"; }
};
template<>
class X<bool> {
public:
void f() { std::cout << "Parameter is bool"; }
};
Traits classes
template <typename T>
T average(std::vector<T> v) {
// ...
};
Problem: if T is int, this won’t return the correct result due to integer division. Solution: introduce helper traits class.
template <typename T>
typename avg_type<T>::type average(std::vector<T> v) { /*...*/ }
template <typename T>
class avg_type {
using type = T;
};
// Specialize for int:
template<>
class avg_type<int> {
using type = double;
};
Problem: this requires specializations for all integral types: int, unsigned int, …
Solution: more helpers! Use std::numeric_limits which has specializations.
template <typename T>
class avg_type {
using type = helper1<T, std::numeric_limits<T>::is_specialized>::type;
};
template <typename T, bool F> // Default: std::numeric_limits<T> is not specialized
class helper1 {
using type = T;
};
template<typename T> // std::numeric_limits has specialization for T
class helper1<T, true> {
using type = helper2<T, std::numeric_limits<T>::is_integer>::type;
};
template <typename T, bool F> // Default: non-integral types
class helper2 {
using type = T;
};
template <typename T> // If integral type, default to double
class helper2<T, true> {
using type = double;
};
Functors (function objects)
A class with an operator() defined.
class MyFunc {
double lambda_;
public:
MyFunc(double l) lambda_(l) {};
double operator() (double x) { return std::exp(x * lambda_); }
};
double l = 5;
MyFunc f(l);
double x; std::cin >> x;
double y = f(x); // exp(5*x);
// Equivalent lambda-expression:
double y2 = [l](double x) { return std::exp(l * x); }(x);
Inheritance and polymorphism
class A {
int apriv_;
public:
A(int ap) : apriv_(ap) {...}
virtual void run() {...}
};
class B : public A {
int bpriv_;
public:
B(int ap, int bp) : bpriv_(bp), A(ap) {...}
void run() {...}
};
Members of A will be inherited into B. virtual causes the compiler to construct a virtual function table, ensuring that when run() is called, the dynamic (as opposed to the static) type determines whether A::run or B::run should be called.
The same could be achieved with generic programming (templates). This produces more code and larger binaries, but is faster at runtime, so it is best used for low-level, small and fast functions (e.g. STL). Object-oriented programming is better suited to larger tasks, e.g. APIs, frameworks etc.
Operators
Assignment operators
- Should be implemented as member functions
- Should return a reference
- Take a const-reference as argument
For instance+=,-=,%=, …
T& T::operator+=(const T& other) {
//...
return *this;
}
Copy-assignment operator
The copy-assignment operator should be implemented following the copy-and-swap idiom to ensure a strong exception guarantee and to avoid code duplication. We define a public friend function swap:
class T {
public:
friend void swap(T& lhs, T& rhs) {
// Enable ADL:
usin std::swap;
// Swap contents of objects...
swap(lhs.member1, rhs.member1);
}
}
And then use that in our copy-assignment operator:
T& T::operator=(T tmp) {
swap(*this, other);
return *this;
}
Arithmetic Operators
- Are best implemented as free functions
- Should defer to the corresponding assignment operator
- Return by value
- Take a const-reference as argument
For instance +, -, %…
T operator+(const& lhs, const& rhs)
return lhs += rhs;
}
Pre- and Post-increment (decrement) operators
Pre-increment operator ++a looks like
T& operator++(T& x);
// Or:
T& T::operator++();
Post-increments operator a++ takes an integer dummy-argument to distinguish from pre-increment:
T& operator++(T& x, int);
// Or:
T& T::operator++(int);
Iterators
Iterator concept summary:
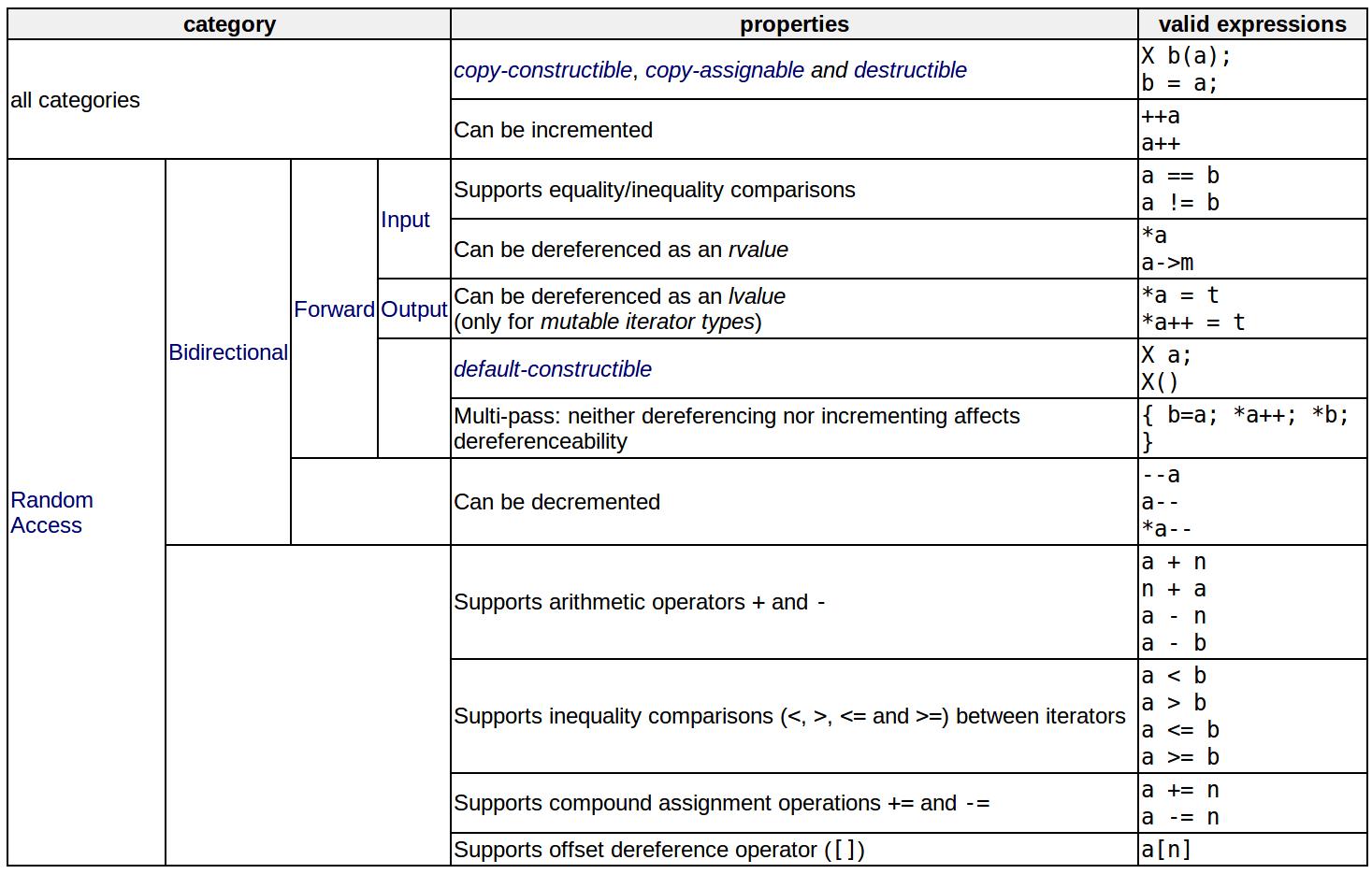
Don’t forget iterators and const-iterators must be implemented separately!
Exceptions
Are defined in <stdexcept> header, and derived from std::exception.
* Logic errors (base classs std::logic_error)
– domain_error: value outside domain of variable
– invalid_argument: argument is invalid
– length_error: size too big
– out_of_range: argument has invalid value
* Runtime errors (base class std::runtime_error)
– range_error: an invalid value occurred in a part of the calculation
– overflow_error: a value got too large
– underflow_error: a value got too cmall
* All take a string as constructor argument (the message)
* All have a method what() containing the error message
Throwing
Using the throw keyword.
if (x == 0) // Throw a char array:
throw "x cannot be 0!";
if (x == 0) // Throw an std::exception object:
throw std::invalid_argument("x cannot be 0!");
Catching
Via the try ... catch block.
try {
std::cout << std::log(-5);
} catch (const std::exception& e) {
std::cerr << e.what() << std::endl;
// Possibly re-throw exception if it can't be handled:
throw;
} catch (...) {
std::cerr << "All other exceptions" << std::endl;
}
Random number generators
As of C++11 in header <random>.
#include <random>
// Mersenne-twisters
std::mt19937 rng1;
std::mt19937_64 rng2;
// lagged Fibonacci generators
std::ranlux24_base rng3;
std::ranlux48_base rng4;
// linear congruential generators
std::minstd_rand0 rng5;
std::minstd_rand rng6;
// Usage:
rng.seed(42); // Set seed
double rand = rng(); // Get next random number
double min = rng.min(); // Min and max possible results
double max = rng.max();
- Always print or log seed so runs are reproducible
- Sources for the seed:
- Set seed as compile-time parameter
- Set seed as input parameter
- Use system time as seed (discouraged)
- Always test multiple different RNGs
Timing execution in C++
#include <chrono>
std::chrono::time_point< std::chrono::high_resolution_clock > start , stop;
start = std::chrono::high_resolution_clock::now();
for (int i = 0; i < 10; i++) {
// Code to be timed...
}
stop = std::chrono::high_resolution_clock::now();
const double time = static_cast<std::chrono::duration<double> >(stop-start).count();
Plotting with matplotlib
import numpy as np
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
t = np.linspace(0, 2*np.pi, 100)
ax.plot(t, np.sin(t), 'b-')
fig.savefig('plot.pdf')
plt.close(fig)
CPU architecture
Cache
Locality (temporal and spatial) of memory calls is very important to high-performance applications. A well-implemented algorithm will make the most out of each cacheline, reducing the number of times cachelines are loaded form memory. Caches can be:
- Directly mapped
- Each memory location can be stored only in one cache location
- “Chache thrashing” occurs when the memory is traversed in strides of the same size as the cache -> at each call, a new cacheline must be loaded -> very slow!
- N-way mapped
- Each memory location may be stored in one of N locations in the cache
- Better than directly mapped memory, but can still suffer from cache thrashing
- Fully associative
- Each memory location can be stored anywhere in the cache
- Best option, but also most expensive
Software optimization
In steps:
- Do not optimize! Get a working draft first.
- Is the program too slow? If so:
- Use compiler optimiziation flags (
-O3etc) - Search for the optimal algorithm
- Use libraries (STL, Eigen, BLAS, LAPACK, etc): avoid duplicating work!
- Use compiler optimiziation flags (
- Is the program still too slow? If so:
- Use profiling to determine which parts are slow
- Investigate slow parts and consider what the optimal data structures are
- Is the algorithm optimal? Check literature.
- Now you can think about optimizing the program!
- Consider vectorization and parallelization
Performance analysis (profiling) tools
Widely used is gprof. Indicates how much time was spent in each function during execution.
1. Compile program with -pg option:
g++ -pg -O3 program.cpp -o program
- Run program
- Profile with
gprof:
gprof ./program > profile.txt
BLAS and LAPACK
BLAS and LAPACK are written in FORTRAN, so we need to interface with it. This is rather cumbersome in practice. A simple example:
#include <iostream>
#include <cstdlib>
// To use the subroutine ddot_, we must declare it as if it were a C function:
extern "C" double ddot_(int& n, double* x, int& incx, double* y, int& incy);
int main() {
// Generate two random vectors
int N = 16384;
double* a = new double[N];
double* b = new double[N];
int seed;
std::cout << "Seed: ";
std::cin >> srand48(seed);
for (int i = 0; i < N; i++) {
a[i] = drand48();
b[i] = drand48();
}
// Use BLAS subroutine to compute dot product:
int inc = 1;
// Lists must be passed as pointers to 1st element
double d = ddot_(N, &a[0], inc, &b[0], inc);
std::cout << "a . b = " << d << std::endl;
delete[] a, b;
}
Input and output
Standard in- and output
In C++, the standard input (stdin) maps to std::cin, and the standard output (stdout) maps to std::cout. std::cerr maps directly to the terminal output.
To redirect output to another program:
./p1.exe | ./p2.exe | ./p3.exe
To redirect output to a file (bash-specific):
./program.exe > output.dat
./program.exe 1> output.dat 2> errors.log
./program.exe &> both.log
Reading and writing files in C++
#include <fstream>
int main() {
std::string file = "out.dat";
// Default mode: fstream::in | fstream::trunc
std::ofstream of(file.c_str());
if (!of) {
std::cerr << "Unable to open file ":
return -1;
}
of << "Hello" << std::endl;
of << "World!" << std::endl;
of.close();
// default mode: fstream::in
std::ifstream fin(file.c_str());
if (!fin) {
std::cerr << "Unable to open file.";
return -1;
}
std::string word;
while (fin >> word) {
std::cout << word << std::endl;
}
fin.close();
}